This week, Brent, Richie, and Tara discuss corruption, resetting query stats, fixing parameter sniffing issues, how to suggest features for our scripts, and why Brent is sporting an Oracle sweatshirt.
Here’s the video on YouTube:
You can register to attend next week’s Office Hours, or subscribe to our podcast to listen on the go.
If you prefer to listen to the audio:
Enjoy the Podcast?
Don’t miss an episode, subscribe via iTunes, Stitcher or RSS.
Leave us a review in iTunes
Office Hours Webcast – 2016-08-31
How can I start learning Service Broker?
Brent Ozar: We might as well go ahead and fire away and starting doing some questions here. Let’s see here, Brandon says, “Do you guys know of any good blogs to read on Service Broker? I have a developer that wants to start using it and I need a crash course in it.” Jorriss Orroz [Richie Rump] has no idea, he’s down below his desk. Tara, have you ever worked with Service Broker?
Tara Kizer: No, we’ve only ever talked about it. We wanted it implemented to start doing different things with jobs, have like this central job server and it would be very smart and it was going to be with Service Broker and it never developed.
Brent Ozar: That’s like how all software design starts. “It’s going to be very smart.” Then in reality it’s like, “I just hope it has all its fingers.” So the two good resources, Klaus Aschenbrenner has a book on Service Broker if you go and hit Amazon.com or whatever you like for books, there’s a book on Service Broker, yellow and black cover. It’s the only book as far as I know. Also look for Adam Machanic, like car mechanic, but M-A-chanic Workbench Service Broker. He has a set of scripts that you can use to learn Service Broker. That’s what I [inaudible 00:01:08 stepped] through for the Microsoft Certified Master exam. It’s just like, hey, here’s a feature, here’s how it works. I don’t know anyone personally using it. I know a lot of people from training classes when I go, “Hey, quick show of hands, how many people are using Service Brokers?” and hands go up. I’m like, “Do you know how it works?” They’re like, “No, the last guy did it.” So somewhere out there in the world there is some guy who’s running around implementing Service Broker like crazy and then the rest of us have to deal with it afterwards.
Richie Rump: It was at my last job, one guy was doing it. I didn’t have the guts to go up to him and say, “Why? What problems are we solving that need Service Broker and that we can’t put on a separate app server with another tool or technology?”
Brent Ozar: Yeah, that’s my thing. That’s what app servers are for, and queues.
Richie Rump: That’s right. There’s a ton of [inaudible 00:01:54] for that.
Brent Ozar: Yeah.
Is it bad if I have one TempDB data file at 170GB, the rest smaller?
Brent Ozar: Kahn says, “Good morning, I added tempdb data files but I’ve noticed that the files are not used or their growing has been a little uneven. My original file was 170 gigs, do I need to make all my additional files 170 gigs too? I don’t have enough space.” So it sounds like to rephrase, you originally had one file that was 170 gigs and you’ve added a few more files but they’re really tiny. What should Kahn do next? [Richie Rumps mimics scene from Star Trek] [Laughter] Star Trek.
Tara Kizer: Check the file sizes, check the autogrowth. I suspect that you have uneven file growth on them which sp_Blitz would tell you about. Run sp_Blitz and it will tell you if anything is off on your tempdb configuration, that’s likely what you have. You probably have the first tempdb file. Might have the ten percent autogrowth by default and maybe you set up the other files to use one gigabyte for instance, you would just need to fix the first file. Make sure that they’re all the same size and they all have the same autogrowth. You can shrink these days. For a few years we thought that there could be corruption that occurs if you shrink tempdb and that ended up not being the case. It was fixed back in SQL 2000, Paul Randal confirmed that with Microsoft a while back.
Brent Ozar: It doesn’t mean they all have to be 170 gigs. You can make them smaller.
Tara Kizer: Yeah, go ahead and shrink that file down. If you need 170 gigabytes, divide 170 gigabytes by the number of files, maybe it’s eight. That’s your target size for each of those files.
My CHECKDB jobs are failing. Now what?
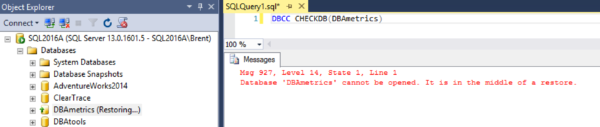
Brent Ozar: Nate says, “I was afraid of corruption.” I know that feeling, Nate. I am afraid of corruption a lot. “On some of our databases because my CHECKDB jobs were failing in production, specifically LiteSpeed CHECKDB jobs.” I didn’t know LiteSpeed ran CHECKDB. “But when I ran Ola Hallengren’s CHECKDBs on the same databases over some backups on a new dev box it was fine. Should I worry?” I don’t know that LiteSpeed… What I’m thinking is maybe you got LiteSpeed jobs that run a restore of the database and run CHECKDB there somewhere else. They could be failing for all kinds of reasons. Run CHECKDB in production. Go ahead and run it in production and see what you get there. I’m not saying you always have to do that, just because you’re getting any corruption warnings, I’d just want to give that a shot and go from there.
Why does sys.dm_exec_query_stats reset?
Brent Ozar: Shawn says, “I’m using the DMV sys.dm_exec_query_stats to find the most frequently run queries. A couple of times a day the counts are getting reset. My server isn’t getting restarted and I swear no one is running DBCC FREEPROCCACHE. What else can reset my query stats?”
Richie Rump: Junior DBA?
Brent Ozar: Junior DBA. It could be so many things. You could be under memory pressure which can start flushing the execution plans and stats out of cache. You could be rebuilding indexes, which will update statistics, which will invalidate query plans. You could be updating statistics. You could be hitting the update stats threshold if you devote 20 percent of the data and a table changes, that can cause plans to get flushed out of cache. Someone could be running sp_recompile. All kinds of stuff that can run to cause that. I would never count on that stuff staying the same for forever but just I wouldn’t expect them to change a few times per day throughout. That would make me suspect memory pressure.
Tara Kizer: Yeah, I had a client maybe a couple months ago that basically it was getting wiped out every five minutes. It was severe memory pressure. We couldn’t even look at the plan cache. I mean it was horrible.
Brent Ozar: Reconfigure is another one that will do it. So if you run a reconfigure statement, if you change certain settings, like someone changes MAXDOP or cost threshold, I remember we had this one client that was changing MAXDOP automatically, like several times a day for different data warehouse loads and that was…
Tara Kizer: Wow. I didn’t know that reconfigure did it. Some clients have asked me for some of the changes that I’ve recommended that they do on their servers. You know, sometimes it’s changing the MAXDOP. They say, “Can you run those during the day?” And I said, “I’ve run those during the day.” So maybe I’ll change my tune. Don’t run the reconfigure, maybe schedule the reconfigure later on.
Brent Ozar: Yeah. I’m all about it. I’m like, “Let me just hit sp_BlitzCache first so that I got good data.”
Tara Kizer: Yeah.
How should I learn Always On Availability Groups?
Brent Ozar: Mark Henry asks, “Do you have a good book on preparing for Always On?” And just one thing we’ll say just because there are grammar Nazis, the grammar Nazis will tell you that—you did great putting a space between Always and On but they will also tell you you need to say Always On Availability Groups because technically failover clusters are also called Always On these days as well. I’m assuming that you mean Always On Availability Groups. I don’t think we’ve seen any good books on it yet. Have you, Tara? Have you seen, or Jorriss, you’ve seen, either, no?
Tara Kizer: No.
Brent Ozar: Yeah, that’s kind of a bummer.
Tara Kizer: I started working on availability groups just from scratch, just playing with it. We wanted to have it in production for a certain application so we started it in the dev environment and learned as we went. It was probably six months before we deployed to production, so we had a fairly good understanding of how to use it. I know that we say that there’s some complexities to it, but it is fairly easy to understand if you spend the time to learn certain topics, like quorum and votes.
Brent Ozar: Really, I think Books Online is pretty good now these days with it too. They go into detail. If anything, it’s too long. It’s really good.
Tara Kizer: And with SQL 2016, they’re making things easier with the Distributed Availability Groups. I think they’re trying to resolve the fact that a lot of companies have had issues with availability groups, when they have a failover availability group for HA at the primary site, DR site, then they lose the connection to the DR site and the whole cluster goes down. So Distributed Availability Groups to me seems like Microsoft is just trying to resolve companies having downtime and really it was because they didn’t set up their systems correctly.
I’m trying to kill Idera SQL DM’s queries, and I’m getting an error.
Brent Ozar: Tim says, “Idera SQL Diagnostic Manager has 31 connections open with a specific wait type, it’s like mSQL exact manager mutex for days. Tried killing two and they’ve been at zero percent rollback for a day. Any suggestions?” Call Idera.
Tara Kizer: Why are you killing them though? What problem are they causing?
Brent Ozar: Yeah, well they’re causing a problem now.
How can I fix parameter sniffing issues?
Brent Ozar: J.H. says, “I thought we might have had a parameter sniffing issue on a couple of complex queries. I’ve tried OPTION (RECOMPILE) but that didn’t help out. What are my options for fixing parameter sniffing issues?” So what are a few things that he could start with thinking about there?
Tara Kizer: Optimize for a specific value, do some testing to see if there’s a specific value that works well for most cases. You know, it’s probably not going to work well for all cases. You probably don’t want to do optimize for unknown. That’s basically the option that we had in SQL 2005 and earlier where we declared a local variable and it just optimizes for an average value and an average value is not good. You might as well spend the time to do some testing to see what value works best in most cases. If OPTION (RECOMPILE) didn’t work, maybe play around with option—I don’t know, MAXDOP wouldn’t solve a parameter sniffing issues. Plan guides. I really like plan guides, when you don’t have the option to modify stored procedures. If you’re the DBA, you can just go ahead and throw that plan guide out there. What I like to tell people though if you do use plan guides, make sure they are stored with the stored procedure in source control because they’re tied to that object. If a developer goes to try to alter the stored procedure in dev and you put the plan guide in there too because you want production to match dev, they’re going to get an error and they’re not going to know what to do with that. So, yeah, attach it to the stored procedure in source control.
Brent Ozar: Yeah, every time you go to change the stored proc, too, you’re going to just want to know that there’s a plan guide because you may need…
Tara Kizer: Yeah, it’s just an easy way to get around having to modify the stored procedure or if your queries are inside the application, locked in the application, then a plan guide is a way to affect the execution plans but if there are stored procedures and you have access to those, you could just do index hints or optimize for, these are the types of things you can do in a plan guide without modifying the code.
Richie Rump: Yeah, the one keyword that pops out to me was complex. Any time that I saw a complex query, I always tried to simplify that, whether that’s by multiple statements or whatnot and make it easier for SQL Server to come up with a good plan.
Tara Kizer: That’s true. Maybe changing the complexity, use temp tables to help that out.
Brent Ozar: Yeah. Also, for an epic post on that, google for “Slow in the App, Fast in SSMS.” Slow in the App, Fast in SSMS. It’s an epic post by Erland Sommarskog, it’s like 50 pages long and it’s fantastic.
Tara Kizer: Does that have to do with the user connection parameters that the application has a different set option than SSMS does? Yeah, every time that I am working with an execution plan in production and my query is fast and the app is still slow, you want to grab the application’s user connection options, the set options, and what I do really quick—I know profiler is a bad thing in production—do a really quick profiler trace in production, even use the GUI. All you need is the existing connection event in there. Start it and then five seconds later stop it and then grab one of the set options from there. Then put that in your Management Studio window and now you’ll have the exact same execution plan as the application and you can start testing from there.
How should I configure identity fields with merge replication?
Brent Ozar: Paul says, “I’m working with merge replication.” My condolences. “I was wondering what your thoughts are on setting up the identity fields to use half of the values on the publisher and the other half on a subscriber like one to two billion on the publisher and two to three billion—” You know, zero to one billion on one, one to three billion on another. All this helps you with is insert conflicts. It doesn’t help you with update conflicts. I do like it just so that you can see where inserts came from, but it’s not like a total panacea. I like starting at positive one on one going up in one, negative one and going down by one on the other two.
Tara Kizer: Yeah, that’s what I would recommend, negative values and positive values. I don’t know about, I mean why would—you mention updates, why would the identity values be updated? That’s pretty rare I would think.
Brent Ozar: Yeah, I’m just saying if you want to figure out where something came from. You can’t tell…
Tara Kizer: Oh, gotcha.
Will index rebuilds be faster in simple recovery model?
Brent Ozar: Mark says, “What are your thoughts on rebuilding all the tables in simple model? We have a very fragmented large database and in testing it takes forever because of the transaction log.” Let me rephrase your question, Mark. If I’m doing a lot of work, is that work faster in simple recovery model as opposed to full recovery model?
Tara Kizer: Absolutely—it’s not for this though. I mean, for bulk-logged, right? The amount of space you’re going to use in the transaction log is still the same in simple recovery model as compared to full recovery model. So that’s not going to help you any, and you’ve lost your recovery points. If you have an outage and you need to do a restore, you won’t be able to do a restore to any point in time while it was in simple model.
Brent Ozar: So what is the difference between simple recovery model and full recovery model?
Tara Kizer: It’s just happens when the transaction completes, is it cleared out of the log. With simple model it is not and with full you have to do a backup log before it’s cleared out. So I don’t know, I don’t know what’s going on with your system because it’s not going to be IO because it’s the same amount of work. So I don’t know.
Brent Ozar: Yeah, what we’re just saying is that simple isn’t going to solve the problem there. If you have crappy IO, it’s going to take a long time to rebuild your indexes.
Tara Kizer: What are you trying to solve? Is your very fragmented large database causing problems? I would bet you don’t have performance problems as a result of it. You might have storage problems as a result of it, but not performance.
Brent Ozar: And you’re making your storage performance worse usually by doing heavy reindex rebuilds. I was just literally emailing back and forth with a client who was trying to do index rebuilds every night and it’s taking longer and longer, making the backups take longer, making the outage windows take longer. I’m like, what problem are you trying to solve here?
Brent Ozar: Michelle asks, “Brent, how did you like Alaska?” I was there last the last week of July, beautiful state. I adore Alaska. I’ve been there I think five, six, seven times now on cruises. I would never want to live there but it’s just really nice to roll through on a boat and eat steak and crabs.
Brent Ozar: Michael says, “Who does the very cool caricatures—I can never…”
Tara Kizer: Caricatures.
Brent Ozar: Cartoons. For our website? It’s a guy by the name of Eric Larsen. If you search for ericlarsenartwork.com he has a cartoonist style. We’re actually on his example pages. He uses us as examples too.
Why does the same query do different numbers of reads?
Brent Ozar: Mandy says, “Hi. SQL 2014 Standard here.” I think we’re going to call you Mandy rather than SQL 2014 Standard. “I’ve seen a proc captured by profiler perform very high reads, in the tens of millions, but when I run the same proc in SSMS with the same parameters I see very few reads. Why the big difference?”
Tara Kizer: Different execution plans. You have different set options, like I just mentioned, your Management Studio window has, I think it’s like one different set option that’s different between Management Studio and what normal applications use, Java, .net, they just have different set options. The set options affects whether or not you’re going to get the same execution plan. So as far as high reads, it’s probably a missing index. Compare the execution plan that the app is getting to the one that you’re getting and maybe you’re going to need to force the plan that you’re getting over to the application, the stored procedure. Put a plan guide in or something, optimize for.
Brent Ozar: I can’t say enough good stuff about that “Slow in the App, Fast in SSMS” blogpost. Huge, epic, really goes into details on them.
Small talk
Brent Ozar: Following up on Tim’s problem with Idera, he says, “Idera won’t [inaudible 00:15:42] the server because it has the maximum number of connections open and they’re all stuck with that wait.” Oh, then definitely call Idera because they may have run into this before. This may be something where they have a query going to hell in a handbasket.
Tara Kizer: There is nothing that we can do to help out with that.
Brent Ozar: “Just restart the server, how bad can it be? Do it live. Oracle guy says so.”
Brent Ozar: Kyle says, “A few weeks ago I sent a question about a nearly 50 gig database.” Here’s the deal, Kyle, if you send in a question and we don’t answer it across the span of a few weeks, either we’re not going to remember it or go post it on Stack Exchange. He says, “The table sizes were small in SSMS reports. Someone else’s…” blah blah blah. “Any thoughts on additional features in Blitz to check for abnormally sized system tables?” So, if you want to suggest features for our scripts, go to firstresponderkit.org. Then click on GitHub up at the top. From there, there’s information about how you can contribute, how you can suggest features, all kinds of good stuff. So go ahead over there.
Why am I getting a login error on my linked server?
Brent Ozar: Ronny says, “Hi guys and Tara. I’ve set up a linked server from server A to server B.” Well, why? Stop doing that. “In the security page for the linked server I’m using this [inaudible 00:17:03] using the security context and I’m using [inaudible 00:17:05] login that I’ve configured on server B. I’m consistently getting a login failure and I know that the login or password is correct. What should I do?”
Tara Kizer: I don’t know how to solve that error but you should not be using that option on your linked server. Does that user only have read access to a particular table? Then maybe use it. But oftentimes what I’ve seen on linked servers is that they point to an SA account and that means every user on your entire system has access to server B using SA and they could do terrible things with it. But why are you getting login fail? I don’t know.
Brent Ozar: The other thing that’s real easy is just trace. Go run a trace over on the server B where the login target is going. What I see over and over again is there is some kind of name resolution problem, like someone thinks they have the right server name but their actually pointed at the wrong server.
Should I put TempDB’s log file on a separate drive in a VM?
Brent Ozar: J.H. asks, “I have a virtual machine. Should I put tempdb on a separate log? Tempdb’s data files on one drive and log files on another. Like tempdb data files on T and the log files on U.” I’ve never seen that recommended even on physical boxes.
Tara Kizer: We always had it separated for my last three jobs. When the SQL 2012 installer GUI came out, it had the separate—didn’t it have the separate [inaudible 00:18:18] for data and log? Yeah, I don’t think that it necessarily makes a difference as far as performance goes but we liked it because if you run out of disk space on one of them, you’re not running out on both. It doesn’t really matter because it’s just tempdb.
Brent Ozar: Yeah.
Tara Kizer: It’s just going to roll back the query. I don’t know. Yeah, we had them separated.
Brent Ozar: “Gotta keep them separated.” [Said to the rhythm of “Come Out and Play” by The Offspring] I have no opinion. If that’s your biggest performance problem, you’re in just a wonderful situation. I normally just throw them all in the same drive and I just like using, say that you’re going to have four data files, just because I have this number of fingers on my hand, say that you’re going to use four data files and one log file, I just take the space available and divide it by five. So if I have 100 gigs available, I’m going to have four 20 gigs data files and one 20 gig log file and just set that up when I have no else clue on how the SQL Server should be set up.
What do you think about SQL Server on Linux?
Brent Ozar: [Inaudible 00:19:09] says, “What do you guys think about SQL Server on Linux?” All right, Richie is making a face. Richie, you answer first.
Richie Rump: I think Linux has plenty of good relational database systems. I’m not quite sure why we need SQL Server on Linux at this point.
Brent Ozar: No one pays Microsoft to use them.
Richie Rump: I guess. There’s got to be some sort of Azure story here about why they’re doing it. I’m not particularly enthusiastic about it. I’d use Postgres on Linux, you know, if it was me. But it’s going to be interesting. It’s going to be interesting to see the bugs coming out of it too.
Brent Ozar: How about you, Tara?
Tara Kizer: Basically the same answer as Richie. What I don’t like about it though is that they have such limited features, they’re going out with a very small—it’s not supporting everything and they’re very selective of who’s getting to use it right now. I think that MVPs are now able to get their hands on it and before they couldn’t but some companies are actually running it and Microsoft is working directly with them. I don’t know why it was needed. Maybe it’s just because some applications require SQL Server and companies don’t like Microsoft products so they want to run Linux as their operating systems for servers at least, probably not for desktops.
Brent Ozar: Yeah, I don’t get it either. The thing that I really don’t get is I don’t see any bloggers or presenters going, “Yeah, I’ve needed this for so long. Here’s why…” I really think it’s a business marketing type decision. The only thing that gives me hope is, Richie kind of hinted at it with maybe it’s an Azure thing. What if you’re the Microsoft sysadmin team responsible for running Azure SQL db? What if you’re frustrated with problems with Windows and running Azure SQL db and you see moving to Linux underpinning that as being a better solution? What if Microsoft constantly likes to tout, “We’ve been running it in the cloud for so long, that’s why SQL Server 2016 is awesome, Azure SQL db has been soaking in it for the last 16 months.” What if Microsoft comes out and says, “We’ve been proving Azure SQL db running on Linux for the last six months and we didn’t even tell you.” That would be kind of amazing. That would be kind of cool if they do that. I just don’t know that it’s going to affect a lot of on-premises shops.
Tara Kizer: Yeah.
Richie Rump: Yeah, sounds like a lot of people are going to end up having to learn Linux because of all this that’s going to happen. “Hey, now I don’t have to pay a Window’s license. You, Bob, you go learn some Linux now.” “Okay.”
Brent Ozar: Costs $10,000 in training to save $1,000 in licensing. Yeah.
Tara Kizer: Yeah, that’s true.
Brent Ozar: Joseph says, regarding the SQL Server on Linux, he says “The biggest problem with SQL Server is the Windows OS.” I would beg to differ. Beg very much to differ.
Brent Ozar: William says, “Brent is wearing an Oracle sweatshirt. Mind blown.” They have a really good sailing team. Also, Larry Ellison owns an island. Who can’t love that? I’ve never used their database platform. They make nice clothes. If Microsoft made sweatshirts that were this nice, I would be all over them. I have an MVP jacket that’s really nice.
Brent Ozar: Thomas says, “You’ll be able to use PowerShell to support Linux.” That’s great, now at least four or five DBAs will be qualified to do it.
Richie Rump: Linux had a Shell problem. What? That doesn’t make sense to me.
Brent Ozar: It’s true. The Linux guys have been using GUIs for the last decade. Linux guys have been begging for, “Please let us stop using this GUI.”
Do UNIONS always perform better than OR filters?
Brent Ozar: Joseph says, “We had a query with an or condition that caused a big, nasty, ugly join. I replaced this with two different queries to join together with a union in order to accomplish the same thing and it returns immediately. Is this a good idea? Should I check for this on a query-by-query basis? Is this a known bug?”
Tara Kizer: I actually learned about that from Jeremiah’s PASS session back in 2011. It was like Refactoring T-SQL, or something like that, was the title of it. I actually blogged about it the next day. I didn’t know that trick and I’ve actually tried to use it a few times since then and sometimes it works and sometimes it doesn’t. I’m not too sure why sometimes—so when I’ve seen or issues with clients, I say, “Consider testing union. I can’t guarantee it’s going to fix the problem. But you should try it out.” The thing I don’t like about that solution is then you have repeated code. Someone goes to make a feature change or a bug fix, you’ve got to remember to do it on every single one of those union queries.
Richie Rump: Yeah, is that a union all or just a straight union?
Tara Kizer: I think that he said replace it with a union and if you can do union all then that’s great, that’s better.
Richie Rump: Okay, all right.
Should I use temp tables or table variables?
Brent Ozar: Nate says, “I listened to a podcast recently where they basically said always use temp tables, never use table variables. What has been you guys’ experience around that?”
Tara Kizer: That is my mantra. We followed the old advice back on 2005—if you have less than 1,000 rows use table variables, more, then use temp tables. So we did that and boy did we have performance issues. We were working with Microsoft engineers and this was an extremely critical system. One of the engineers suggested, “Oh, just try swapping the table variable for a temp table. Let’s see what happens.” Boom. Performance was solved. I mean, it was amazing. And there was only like one to five rows in the table. So it was a really small dataset. Since then, I will not even use a table variable except in ad hoc, if I’m doing like a forum, if I’m trying to answer a question on a forum, I’ll go ahead and use a table variable in my Management Studio window, but that’s it. Table variables I think are just terrible for performance. You know, if Microsoft did make improvements in, what is it, 2014 or 2016? But it’s still not good enough.
Brent Ozar: Yeah, I bet the podcast you listened to was Wayne Sheffield on Carlos L. Chacon’s SQL Data Partners Podcast which is a fun—if you like podcasts—and of course, some of you are listening to this—SQL Data Partners Podcast is good. It kind of takes presentations and turns them into podcasts. Wayne Sheffield knows what he’s talking about. His evidence is good. Nate says, “Yes, Brent nailed it.” Yep, that’s the one. It’s good stuff.
Tara Kizer: You have an incredible memory by the way, Brent. You just remember all these things. I’m just like, “I know I heard about this somewhere. I can’t think of what to Google to find it.” From now on it doesn’t matter if it’s about SQL Server, it could just be about cooking, I’m going to ask you. Maybe you came across it.
Richie Rump: Yeah. I’m like, “I think I was on that podcast once. I’m not sure. Was I? I don’t remember.”
Brent Ozar: “I was on roundtable with, I can tell you people were on it.”
Richie Rump: Oh my god.
Tara Kizer: My 8-year-old son has an amazing memory. He always has. We backpacking recently with a family and there was boy. Someone asked the other boy whether or not he remembers getting bit by red ants. He’s like, “I don’t think I ever have.” My son said, “Yeah, you did. Several months ago you got bitten by a whole…” and he described the place. The kids like, “Oh yeah, that’s right.” You’d think he would remember getting a whole bunch of red ants on you and them biting you.
Brent Ozar: You wonder like what shapes kids and how they have these memories that he’s going to remember forever.
Tara Kizer: Yeah. It’s not a good thing sometimes, that’s for sure.
Brent Ozar: No. All right. Thanks everybody for hanging out with us this week. It’s always a pleasure hearing your questions. We will see you guys next week on the podcast and on Office Hours. Adios, everybody.
Tara Kizer: Bye.
Going to Seattle in October? Our 2-day class is almost full. Register now.
![]()