This week, Brent, Richie, Erik, and Tara get together in Round Rock, TX, for Dell DBA Days, to talk through your SQL questions and answers. They discuss what they are working on at Dell during the event, as well as Windows Kerberos and NTLM Authentication, Always On Availability Groups, Microsoft’s Document DB, automating restore databases to other servers, why they are wearing “fun” hats, and much, much more!
Here’s the video on YouTube:
You can register to attend next week’s Office Hours, or subscribe to our podcast to listen on the go.
If you prefer to listen to the audio:
Office Hours Webcast – 2016-08-10
Brent Ozar: All right, it’s 11:01.
Erik Darling: Which means it’s 12:01.
Tara Kizer: It’s 9:01 right there.
Brent Ozar: So this week we are in Round Rock, Texas at Dell. We could turn this around and show you the other way, but it’s a whole rack of servers and then you hear all the sound humming from all the servers yelling at each other. So this week we’re actually in the same room together. Oh my god.
Erik Darling: Amazing.
Brent Ozar: Unbelievable.
Erik Darling: Reasonably priced Round Rock.
Brent Ozar: And we had a reasonably priced dinner last night.
Erik Darling: It was great.
Tara Kizer: With such great weather.
Brent Ozar: If you ever are looking for a place to come for vacation, Round Rock in August is not an excellent choice. Not a very good choice at all.
Richie Rump: Hades would be cooler.
What We’re Testing at Dell DBA Days
Brent Ozar: I thought you were going to say Haiti, which would also be cooler. Holy smokes. So yeah, it’s been 100 every day. So today, Richie, what are you working on today?
Richie Rump: I’m working on testing loads with bulk loads and C# and that would be today. Tomorrow I’ll be doing things like what if you’re using selects and doing raw inserts and concatenation? What about entity framework? What [inaudible 00:01:11] entity framework inserts? How long will it take to do 100,000 inserts with that? Will it even finish?
Brent Ozar: Now, I keep hearing you swearing, dropping all kinds of like… So what kinds of errors have you been running into?
Richie Rump: Oh, wow. I’ve been running into errors just getting data out and putting it into a format to consume via programmatically. I have a gig file that I’ve created of just straight JSON, of just SQL, from system Stack Overflow. Reading that and getting into the application and then being able to put it back in has been very challenging with the size of data that we’re dealing with, right? I tried with one million, half a million. Now, I’m down to 100,000, seeing how that works. I’m running out of memory. That’s been the biggest problem.
Brent Ozar: But to be fair, on your laptop.
Richie Rump: On my laptop. But a lot of this stuff would be running in some app server, depending on if it’s a client or whatever. So I don’t really want to run it on the big, beefy servers because that’s kind of cheating.
Brent Ozar: That’s fair.
Richie Rump: It’s kind of cheating. You’re not going to have app servers the size of the stuff that we’ve got.
Erik Darling: App servers do not get the same love.
Brent Ozar: In many cases SQL servers don’t even get the same love.
Erik Darling: That’s true. Sometimes they’re on the same hardware.
Brent Ozar: Tara, what are you testing so far today?
Tara Kizer: I’ve been working on backup performance, seeing if there’s any differences in backup times between 2014 and 2016, since they say 2016 “just runs faster.” Not noticing any performance gains with backups at least, not that we were expecting any, but it was a good test. Now, just testing all the different parameters that you can use to affect the backup performance and seeing what works best.
Brent Ozar: When I was a database administrator, I don’t think I ever touched any of those settings, except for the number files. I played with the number files but beyond that, I was like, “There’s a what?” Erik, how about you?
Erik Darling: I am testing a few different things. I’m testing some stuff from the 2016 “it just runs faster” line. The first thing I’m testing is DBCC CHECKDB which it just runs faster because it skips some stuff. But it seems to be going pretty well. I have it tested on 2016. I’m now running commensurate tests on 2014. I’m also testing a feature where 2016 has multiple log writers. So doing a bunch of single row inserts should theoretically go faster on 2016 but that test is running as we speak right now. The other thing that I’m planning on checking is—oh, gosh, what was it? The soft NUMA workload scaling. I’m going to try and put together something that checks on that and see if it actually is 30 percent faster with MAXDOP set to the number of cores in a socket.
Brent Ozar: It’s weird. So the way that they do soft NUMA on 2016, I hadn’t seen this. We’re dealing with these 72 core systems where, theoretically, each NUMA node really has 36 cores but we see, when we run sp_Blitz will show you—with CheckServerInfo equals 1—will show you how SQL server has divided it up in multiple NUMA nodes.
Erik Darling: Yeah, pretty crazy stuff.
Brent Ozar: You don’t have to do anything with it. It just happens automatically. As to whether or not it just runs faster, the jury is still out. Overnight, I ran a load test on, I would add one index, run CHECKTABLE, add another index, run CHECKTABLE. I wanted to see if it scaled exactly linearly or approximately linearly or if I hit any kind of hockey stick where as I started to run into problems with the table being larger than memory, where would I run into problems with this thing taking a stratospheric amount of time? And because we have a relatively limited amount of time here with the boxes, what I just do is I’ve been running the tests and just dumping the data into a database. I’m not even analyzing the outputs of it yet. In the coming weeks, we’ll start to digest and slice and dice these so that we can go give you blogposts on what are the results of these, lay them out in a nice visual fashion so I can see graphs. But the next thing will be that I want to play around with, is memory grants. I want to play around purposely constructed—it’s easy to write bad memory grants on the sizes of data that we have here and then see if I can easily reproduce stuff like RESOURCE_SEMAPHORE query compile issues and see if I get different memory grant estimations back between 2012 and then 2016 CE.
Erik Darling: The query compile ones, for me, have always been a lot harder to hit than just the straight RESOURCE_SEMAPHORE ones. Anyone can blow up memory by getting the query compile ones. Getting SQL to the point where it can’t get memory to even figure out how to run a query is impressive.
Brent Ozar: Yes, which now it’s easier with 72 cores, I can actually have enough running queries and really just drain this guy dry.
Richie Rump: You guys have been.
Brent Ozar: Yes.
Richie Rump: You guys have definitely been draining them.
Brent Ozar: I love this stuff. Let’s see here. So if you guys have questions, now is the chance. There’s only like 20 of you guys in here. Now is the chance to go put your questions in because we usually go through these chronologically. We tend to hit the ones that come in early first. If you add more questions later, you may get missed. You may not actually get the answer in. If you want, we’ll go ahead and get started just since we have folks in here already. We’ll go ahead and start going through these.
What’s the difference between Kerberos and NTLM for Windows authentication?
Brent Ozar: Nate says, “First off, thanks to you all guys for doing this. The videos and transcripts are a big help to me and the rest of the community. How much of a difference is there between using Kerberos and NTLM for Windows authentication?” Oh, you’re breaking up. I can’t…
[Laughter]
So do any of you guys know anything about NTLM versus Kerberos? Because I am certainly not that guy.
Tara Kizer: Microsoft says Kerberos is the recommendation so we use Kerberos for now.
Erik Darling: All the applications I’ve ever dealt with use Kerberos too. There was never any, “Oh, you have to use NTLM for this one weird thing.” It was always, like Richie’s shirt: Kerby, Kerby, Kerby.
Richie Rump: Kirby Link.
Erik Darling: Yeah, whatever. I get it. I get it…
Brent Ozar: I have no idea what’s happening here. Graham says, “Kerberos is OS agnostic and more complicated than NTLM.”
Erik Darling: Thanks, Graham.
Tara Kizer: It’s definitely more complicated.
Should I use managed service accounts?
Brent Ozar: Graham says, “I want to use managed service accounts for SQL Server service account. Did you use them?” Did you use MSAs?
Tara Kizer: Nope.
Richie Rump: No.
Erik Darling: No.
Brent Ozar: It was one of those where it came out in Books Online and Microsoft was like, “Yeah, we have these now.” I didn’t see anybody using them. I know you couldn’t use them with AlwaysOn Availability Groups when they first came out and I know that’s fixed now but I just don’t know, because I don’t really know what problem it solves.
Tara Kizer: What’s the difference between MSAs and regular?
Brent Ozar: I think you don’t have to have the password or something like that? Like SQL Server manages or Windows manages the password for you…
Jason Hall: [Inaudible 00:07:43] I don’t know how it works behind the scenes but I know that’s the advantage of it is they can change the password in the backend and it propagates out to all the…
Brent Ozar: So we have here Jason Hall from Dell as well.
Richie Rump: All he is just fingers.
Brent Ozar: Magic, vibrating fingers.
Should I get my own OU in Active Directory?
Brent Ozar: Graham continues: “I would like to manage my own OU in Active Directory, but it’s a pending review in my organization. Is asking to manage my own OU too much? Current management is no bueno.” I never, I don’t know—well, what do you guys feel about that?
Erik Darling: I always wanted my Active Directory guy to just tell me what accounts I can use and just run with it. Separate myself from it a bit.
Tara Kizer: I believe we managed our own OU at one of the corporations I was at, but that’s because we were very trusted by the IT team. But other than that, and I’m not even too sure why we needed to manage it, because it’s not like it was changing very often.
Brent Ozar: If your AD admins are so slow in getting you what you want, if you need to spin up that many SQL servers with different service accounts all the time and virtual computer objects, I would probably ask you why you want that. You know, just what the big benefit is for you to have the rapidly changing AD stuff. I don’t think I’ve ever heard of a DBA getting to manage—I hear a lot of DBAs who are sysadmins who are Active Directory admins, and I was that way. But splitting off into separate OU, I never got that.
Erik Darling: Because like most of the time when you set it up, as long as it’s right the first time, you get like the set service principle stuff, privileges—like the, what is it? Delegate something. It’s another setting that has to do with delegation.
Brent Ozar: Cluster and all that.
Erik Darling: Yeah, yeah, so as long as you get that stuff set up the first time, there’s not really a need to go back and tinker with it again after that. Just set the password to never expire and roll with it. I think managed server accounts, much like in SQL server, the multiple active results sets where like kind of a checkbox for one customer, one big customer who wanted something. They just said, “We have it now.”
Tara Kizer: One of the corporations I worked at, we had about 700 SQL Servers, and we were spinning up SQL Servers pretty quickly. After moving from one service account to—each server got its own service account and the agent got its own. We required the AD team, or whoever was setting up the accounts, to create 100 new accounts for us. That way we didn’t have to keep requesting it and waiting on them. If we ever ran out, we would ask for another 100 of these.
Brent Ozar: I bet they were like pushing you, “Here’s your own OU. Please.”
Tara Kizer: It wasn’t the sysadmins that had to do this. They’d given some other help desk people privileges to add the accounts. So it wasn’t a big deal to them, but it did take a while for them to turn around those 100 accounts.
Brent Ozar: It’s not like they’re adding value. It’s not like they’re doing some—if you’re letting help desk people do it. Graham says he wants his own OU because there’s an AD overhaul going on. “Thanks for the recommendations.”
Erik Darling: There’s the benefit, good luck.
Are there any improvements in SQL 2016’s Always On Availability Groups?
Brent Ozar: Mark asks, “Any improvements in SQL Server 2016 with AlwaysOn?”
Erik Darling: I don’t know if I’d call them improvements, but there are some new features. One that I’ve been writing about a lot is, oh god, what do you call it?
Tara Kizer: Direct seeding.
Erik Darling: Yeah, that thing. I have a whole series of blogposts about direct seeding, what’s kind of good about it, what’s kind of bad about it. Things it works with, things it doesn’t work with. I recommend you go back and take a look at that. The problem that solves is actually really cool, because I look on dba.stackexchange a lot, and there are constantly availability group questions where people want to know, “Is there a way that I can automatically get a database added to my availability group and seed it out without writing a script?” Okay, we added backup, restore, blah blah blah. There never was that, but direct seeding attempts to solve that problem. It’s still got some stuff to work out, it’s a little bit janky, it’s the first run of it. I’ve got some faith in it. I think it’s going to end up being all right.
Brent Ozar: You’re so polite.
Erik Darling: I try. I’m in Texas, I’m trying to be a gentleman.
Brent Ozar: There we go.
Erik Darling: I’m making a nod on that.
Brent Ozar: Multiple availability groups, so you get an AG of AGs is the new distributed availability groups feature. No GUI. But it lets you have one AG in one cluster, another AG in another Windows cluster. Can be in different Windows domains even. And then another AG on top of that. So thinking with it as an AG of AGs. Sounds kind of crazy and complicated, but the nice part is whenever you want to roll out SQL Server 4096 or whatever comes next, then you can go build a separate AG there and directly move your data across from one AG to another. No GUI.
Tara Kizer: It sounds from the documentation that I was reading about, it sounds like they’re trying to solve people that have disaster recovery solutions so that you don’t have to have an AG across both data centers. To me, it sounds like they’re trying to solve how people are configuring their AGs in 2012 and 2014 and not having the quorum in both set up properly. Which you can do it in 2012 and 2014, if you do it correctly. But distributed availability groups makes it simpler.
Brent Ozar: You nailed it when you said they were fixing kind of the wrong problem, is that because it’s built on top of clustering, the cluster can fail, so people kind of want a plan B. More clusters! I’m like, how about you not use clustering as the base level technology? But of course that ship has just sailed. It is what it is.
Erik Darling: I think you also get—what is it? You get some more replicas now, you also have parallel redo on the…
Brent Ozar: Yeah, performance improvements.
Erik Darling: Yeah, performance improvements and probably some compression stuff they improved. I couldn’t tell you more about that.
Brent Ozar: It’s nice to see that they’re actually investing in that technology, that things are getting better there.
Why are you wearing the fun hats?
Brent Ozar: Amber asks, “Why are you guys wearing the fun hats?”
Richie Rump: We’re always wearing these hats.
Tara Kizer: Howdy.
Brent Ozar: We are in Texas. We’re in Round Rock, Texas, for Dell DBA Days. There’s a big, ginormous rack of servers behind you. There’s a wall, a bar over on this other side of the room. We’re eating Mexican food and barbecue and all kinds of things that are going to kill us, steak.
Erik Darling: I think this means that Amber has not been tuning into DBA Days, which is a darn tootin’ shame.
Brent Ozar: Amber, it’s totally free. If you go to http://brentozar.com/go/DellDBADays, we still have three webcasts left on Thursday and Friday. What’s coming up tomorrow?
Erik Darling: I’m doing a webcast tomorrow called Downtime Train, which explores some of the bad things that can happen when you don’t pay enough attention to tempdb.
Richie Rump: Will you be cosplaying as Rod Stewart?
Erik Darling: The question is, when am I not? That’s the secret, I’m always Rod Stewart.
Brent Ozar: Then we’re also doing one on Thursday afternoon, talking about the performance overhead of various features, where we’re going to look at some of the results that we’ve gotten and just talk about the tests that we ran and what kind of performance impacts that we saw. Then Friday we’re going to start pulling plugs and doing diabolical things to SQL Server in order to make them break, just for fun. Because when we walk out of here, we want to leave the servers in a smoking pile of rubble, just as we leave.
[Laughter]
Appreciate the sponsorships, see you next year!
Where can I get help with SPN configuration?
Brent Ozar: Nate says, “Thanks for addressing my question earlier.” Let’s see, Nate’s question was the one about Kerberos and NTLM. He says, “Our environment was never set up with correct SPNs.” Was anyone’s, though, really, when you get right down to it? So all SQL connections are using NTLMs, sounds like it’s time to saddle up and bring it up with the domain names.” One of my favorite, if you’re looking for help on the setspn thing, if you Google for “setspn Robert Davis,” Robert Davis has a post talking about how you go about identifying when you have the service provider name problems and how you go about fixing them. I used to have that stored in my bookmarks, I go back to that every time.
Erik Darling: One thing that I notice frequently when we check up on clients is that in the error log they will have “SQL could not” whatever “with SPN handshake.” I’m like, ugh?
Brent Ozar: Do you ever tell them what to do to fix it?
Richie Rump: No, because it’s never related to a problem.
Tara Kizer: [Looks at laptop screen] We knew it.
Brent Ozar: Folks, you’re saying that the webcast quality seems to be a little bit above and beyond what the Dell DBA Days one is. Yes, we’re using different platform here so it’s a little nicer.
Erik Darling: Thank Richie for setting up the microphone.
Brent Ozar: Yes, and the camera, and yes. Also, this tells you what it’s like here at Dell DBA Days. We are holding the webcam up with a couple of SSDs, that’s how much hardware we have to play around with. We’re just using them for all over the stuff.
Richie Rump: That’s funny, but it’s not a joke. It’s reality.
Brent Ozar: We really are.
Richie Rump: Some SSDs holding up the…
Brent Ozar: To those of you who are watching the Periscope, you can actually see the SSDs now over in the Periscope side.
Erik Darling: So if you want to see even more of us…
Brent Ozar: Yeah, we’re everywhere. All of us.
What’s the impact of snapshot isolation levels on tempdb?
Brent Ozar: Mandy asks, “Erik, in your Downtime Train …” She even got it spelled correctly. “Downtime Train webinar—will you be covering tempdb impact of snapshot isolation levels?”
Erik Darling: Oh, Mandy, yes. Yeah, that’s actually what makes things break at the end of the day is that tempdb wasn’t watched appropriately and someone went and turned on a cool feature and then tempdb stopped responding.
Brent Ozar: BEGIN TRAN.
Tara Kizer: I once had a database, it was a Java application, and…
Brent Ozar: You can stop the story there, it sounds terrifying.
Erik Darling: Yeah, we get it.
Tara Kizer: There were times where, and I don’t remember what it was, hibernate maybe, but there was a bug where it would just do a BEGIN TRAN, and it just would forget to commit. We were using RCSI, similar to snapshot isolation, on the database. Eventually tempdb would run out of space. That’s when I learned about the version store, because we were new to RCSI at the time, it was many years ago, back around 2005. I had to write a job to start looking for this condition and kill that. I just wouldn’t kill an open transaction just because, but if it had been open for several hours, you know, then I’d have to get rid of it so we wouldn’t encounter this tempdb issue. When I left that company, just three years ago, that issue still existed. So it was years of this bug in place, and it wasn’t an application bug, it was the framework they were using.
Erik Darling: I dealt with a very similar bug with a third party vendor back when I worked at a market research company. What would happen sometimes is a telephone interviewer would start asking a question and they would go to edit something. So SQL would start to issue an update to the table to mark a response, but it wouldn’t commit until they hit the next button, so there’d be all these…
Richie Rump: Bad developer.
Erik Darling: “What happened?” “I don’t know.” This was like my first feet in the water with SQL thing too, so I would see this stuff and just… I don’t know.
Brent Ozar: Is this normal? yeah.
Richie Rump: Well, it shouldn’t be normal, how’s that?
Erik Darling: We would see this stuff pile up and they were like, “I can’t do the survey.” “Nope, you can’t.”
Brent Ozar: Kevin says, “Microsoft has a free tool for Kerberos called Kerberos Configuration Manager.” Never seen that. That is pretty sweet, it probably hasn’t been updated in 14 years and has 60 known bugs.
Richie Rump: Why does everything have to be a manager of something?
Brent Ozar: Or enterprise.
Richie Rump: Or enterprise. Maybe enterprise manager of something.
Brent Ozar: As your enterprise manager of Kerberos…
What’s using all the space in my database?
Brent Ozar: Kyle asks, “I have a database which is using 40 gigs of space, and I don’t know where that space is being used. I use various queries to list space usage for table, including the built in SQL Server Management Studios reports, and it shows maybe five gigs use of space usage in table. I’ve tried DBCC UPDATE USAGE and there’s no change. There’ve been no recent upgrades or [inaudible 00:19:31] usage. Where should I look to see what’s taking up that space?”
Erik Darling: Heaps.
Brent Ozar: Oh, I like that. So where would you look to see that?
Erik Darling: You can actually run sp_BlitzIndex and you can figure out if you have heaps with a lot of deletes against them. I talked about it a little bit earlier, when you delete from heaps, you don’t actually deallocate pages from the table, you just delete rows from the pages. So you could have gigantic heaps with very little data in them. That’s very common if people have staging tables or they’re just deleting from the staging table rather than truncating.
Tara Kizer: So that space usage per table report would reflect that?
Brent Ozar: I have no idea.
Erik Darling: sp_BlitzIndex would.
Brent Ozar: But he’s saying he ran the space usage…
Erik Darling: Oh, yeah, I’m not sure what that would show for that.
Tara Kizer: Since you’re looking at reports in SSMS, look at the disk usage. Not per table, just disk usage, and you’ll probably see it’s free space.
Brent Ozar: I like that.
Erik Darling: That doesn’t mean you should shrink your database.
Brent Ozar: Why not? I hear so many good things about shrinking databases. It’s all over the web, everyone says that I should do it.
Erik Darling: Well you have to figure out if that free space is actually a problem or not. If it’s a 40 gig database, if you have, hopefully, you’re living in recent history and you have at least a 100 gig or 200 gig drive, it’s probably not a big deal.
Brent Ozar: True. The solid-state drives we’re using to hold up the webcam are 120 gig drives, that’s why they’re lying around in here like popcorn after a movie theater closes. Because you can buy a 120 gig drive these days, is like $80 on Amazon. It’s really cheap.
Erik Darling: So if your database grew to be that size once, there’s a pretty good chance it’s going to be that size again. If you just kind of leave it how it is, you just save yourself the trouble of having to regrow your data file.
Which conference should I attend, the PASS Summit or SQL Intersection?
Brent Ozar: Nate asks a question, “This year in October, both the PASS Summit and SQLintersection are two different conferences that are scheduled at the same time. Which would you guys recommend?”
Tara Kizer: Both.
[Laughter]
Brent Ozar: That’s hard to go wrong.
Erik Darling: I would recommend coming to our precon then going to Intersections.
Richie Rump: Interesting.
Brent Ozar: That’s what I did last year. So what do you guys recommend and why?
Tara Kizer: I haven’t been to SQLintersections, but I want to go.
Brent Ozar: Especially because it’s in Vegas.
Tara Kizer: In Vegas, yeah. But I don’t want to miss PASS. I don’t know. Tough.
Richie Rump: What are you trying to get out of a conference? They are two very different conferences, right?
Brent Ozar: That’s a great question.
Richie Rump: If you’re going to PASS, it’s going to be much more of a community level event, much more of real people who use these technologies day in and day out, they’re going to be the ones presenting. Microsoft presenters are there as well. Intersections, there’s a whole bunch of other different technologies going on at the same time. If you’re more of a widespread, “Hey, I like a little dev, I like a little of this, a little of that,” Intersections may be something good for you.
Brent Ozar: That’s true. I go back and forth to them all the time. I like both of them. PASS is kind of life changing because you see 5,000 people in the same conference center that do the same thing that you do. There are 25 tracks, or whatever it is, going on at exactly the same time. So there’s a bunch of the topics covering everything you could possibly imagine, but only SQL Server. The presentations can be hit or miss, because you got to remember that a lot of us are just community presenters who don’t present full time, they’re going to share what they learn. It’s a lot of real world type stuff there. So don’t get hung up as much on the quality of the presentations, as much as it is you’re getting learning from somebody. Don’t be afraid to go talk to them afterwards. A lot of us will go through, I used when I was attending, just make this list of sessions that I wanted to run from, from one to the next. Stop and just find the ones you really want and talk to people afterwards, go talk to the presenter, take your time.
Erik Darling: If you want five different introductions to R, go to the Summit.
Brent Ozar: Five sessions on an intro to R. Intersections, the presenters tend to be a little bit more full time presenter-y, like professional trainers. There’s less simultaneous tracks, there’s only going to be like three or four SQL Server tracks simultaneously. So you don’t quite get the breadth. But just, you know, six of one, half dozen of the other. Seattle in October sucks. Vegas is a little bit more fun. So if you’re going just as an excuse to write a check and go party somewhere, go to Vegas.
Richie Rump: Yeah. I would say probably the “hallway track” at PASS is probably best. The hallway track being, “Hey, I’m not going to go to a session, but I’m going to talk to people just hanging around and get learning from that.” I would say PASS is probably best for that. I remember I was at PASS and I had cornered one of the Microsoft guys. I got a two-hour conversation on just the things that I was looking for. So I had like my own private session for a couple hours. Those are the kind of cool things that I think that happens at PASS that maybe not so much will happen at some other conferences.
Brent Ozar: The after hours track at PASS is huge too. Like there’s so many parties every night that vendors put on, that individuals do, karaoke-type things. Intersections, at 5 o’clock or whatever it is, everyone disappears. Everybody goes off and does their own thing. The speakers still get together, and if you’re an attendee that wants to get to the speakers, go talk to one of the speakers and they’ll tell you wherever they’re going off as a group that night. It’s just very different from the SQL family thing that a lot of people talk about at PASS.
Does the Senior DBA class cover the cloud?
Brent Ozar: Amber says, “Does your senior DBA class include cloud technologies as well?” We do one hour on the differences between platform as a service and infrastructure as a service, and why senior DBAs typically want infrastructure as a service, but it is only one hour. Typically, if you want more in-depth cloud stuff, here’s the thing, it changes so fast that generally you don’t want to go get a regular cloud training class on it. You want to go directly to the cloud vendor and explain to him what your use case is and they’ll help get you set up.
Have you used Microsoft’s DocumentDB?
Brent Ozar: Graham asks, “Any of you guys have any experience with Microsoft’s DocumentDB?” Have you seen anybody using that, Richie?
Richie Rump: I haven’t seen really many people use it hardly at all. From what I understand, it’s very similar to the stuff they have over at Amazon, and Dynamo and things like that. Which I’ve worked with.
Brent Ozar: DocumentDB?
Richie Rump: No, I’ve worked with Dynamo, I haven’t worked with DocumentDB yet. It’s on the list of things to do, and it’s very long.
Brent Ozar: Tell me about the kinds of experiences that you had with Dynamo.
Richie Rump: With Dynamo, essentially you’re just going to have one flat table, and it’s going to be very fast in that flat table. If you need to run with one particular index on it, you can do that. Any more than that, you’re kind of sunk. You’re not going to want to do like a lot of OLTP type stuff.
Brent Ozar: Relational…
Richie Rump: Yeah, like have my whole bunch of other tables and they all relate to one another. You probably want one unique thing in one table and then have something else that’s not related in another table. Very fast, great performant, but you’re not going to get the niceties of transactions and things like that, ASCII compliance, that you would get with your regular SQL.
Brent Ozar: Relationals.
Richie Rump: Yeah.
Brent Ozar: The thing I would look at with DocumentDB is the maximum size of the document, and then the maximum size of a collection as well. I forget what DocumentDB calls the collection thing, but it’s fairly limited, as is Amazon’s. They’re both pretty limited.
Richie Rump: Yeah, we were messing with some of that stuff a few weeks ago. We had decided not to put it inside the database but move it off to like S3 storage or BLOB storage. Because from a cost and from pulling it out, and doing all that stuff, it just didn’t make sense.
Brent Ozar: And the file size.
Richie Rump: Yeah, the file size. It’s that learning stuff that you just learn, it’s like, “Oh, this is not like a regular database. This is something completely different.”
Brent Ozar: And it changes so fast. Every six months, you have huge, massive changes with it. We know the new product manager for DocumentDB, Denny Lee, was at Microsoft years ago, worked in the SQL CAT team and then left to go do NoSQL work and then came back to Microsoft. So, they’re investing in it at least. They hired a new product manager for it.
Does optimize for ad hoc help performance?
Brent Ozar: Dennis asks, “In your experience, when you’re dealing with SQL Server 20012 …”
[Laughter]
We don’t deal with that a lot, but we’ll tell you about its grandpa, 2012. “Does turning on optimize for ad hoc help performance when we have a few stored procs and a whole bunch of ad hoc developers?
Tara Kizer: I don’t know that it helps necessarily with performance, but it helps with memory. You’re going to use less memory for your ad hoc plans because with that setting on, it’s going to mean that when the query runs the first time, the stub record is going to be loaded into the plan cache rather than the full execution plan. If that query runs again, then it’ll load the full execution plan. A lot of times with ad hoc queries, they only ever run once. I was actually investigating this last week because a client asked if entity framework queries come in as ad hoc because they had most of their plan cache was ad hoc queries. They said, “We can’t possibly have that many employees running queries to have caused this.” I did a little research, and there was a Stack Exchange answer that said, “Yes, entity framework comes in as ad hoc.” So I would recommend that if you are using entity framework, to go ahead and enable this, especially if the ad hoc query bucket is a significant percentage of your plan cache. That way, you can use less memory for the plan cache.
Erik Darling: Group question, because I’ve heard rumors but I’ve never actually witnessed it. What are situations where turning it on could backfire?
Tara Kizer: There’s one, and it’s when a query runs twice and no more times than twice.
Brent Ozar: Because you compile twice.
Tara Kizer: Compile twice, yeah. That’s usually not the case, it’s usually one or more. Usually one.
Brent Ozar: I’ve seen people add it in their setup checklist just as a default, and I never raise that. I’m like, “Okay, that cool. Yeah. If you want to use it, that’s fine.”
I’m an MCSE – what should I do now that the MCM is gone?
Brent Ozar: Alberto says, “I’m a Venezuelan guy currently living in Argentina.” You sound like a good time. I like you already. “I’m an MCSE in SQL Server and I would like to know what should be my next step now that the MCM is gone.” I don’t know, what country do you guys think he should move to next?
Erik Darling: Go for Brazil.
Tara Kizer: Brazil, yeah.
Richie Rump: Chile.
Brent Ozar: Yeah, the mountains are beautiful. All right, sadly, there is no advanced certification. There’s Microsoft’s new Big Data University, what is it that they call that thing? So, there’s some kind of Big Data University thing that they’re kind of positioning as a college degree except it’s not. It’s not like an accredited kind of thing. Sadly, you are at the pinnacle, and not just because you’re living in cool places. You’re as good as it gets. I would say, instead of thinking about spending time studying for a cert, now’s the time where you start giving back. You start writing blogs, doing presentations, because that will enrich your career way more than a certification will. Anybody can get a certification.
Erik Darling: Could try getting a job.
Brent Ozar: Try getting a job, yeah.
Richie Rump: It’s a data science “degree,” right? It’s “degree.”
Brent Ozar: It’s like the antiperspirant, it’s not really a degree.
Tara Kizer: So who’s going to be going after those data scientists? Wouldn’t that be on the BI side? And if you’re an MCSE asking about MCM and other certifications, probably not interested in data scientists.
Brent Ozar: God, I hope not. Nothing against data science. It’s wonderful.
Erik Darling: It’s a very specific career path, not necessarily one for DBAs.
Tara Kizer: It’s not DBAs, yeah.
Richie Rump: [Inaudible 00:30:39] Buck Woody doesn’t pop up behind you, [crosstalk 00:30:41] data science there.
Tara Kizer: We’re not talking bad about it, it’s just DBAs aren’t going to be going down that track, probably.
Brent Ozar: He had a blogpost recently where he said don’t learn data science. He said, “Whatever you do, don’t learn data science. Learn specific topics. Pick things, I want to solve this problem this week.” Because it’s going to take you five years to be a data scientist, just pick things you can nibble off in a week.
I have a really long question…
Brent Ozar: David says, “I’ve read that SSMS 2016 is no longer directly connected to the version of database that you’re running. I’ve downloaded SSMS 2016 and I ran into what must be an easy problem.” Then he lists four pages of things. Hold on, he says, “I’m trying to import…”
Tara Kizer: I think the answer’s going to be we don’t know.
Brent Ozar: Just at a glance, what I would do is any time you have a multi paragraph thing with an error message, just post it on Stack Exchange. Go to dba.stackexchange.com and you can post it over there. Hope people can get you the exact answer on that one.
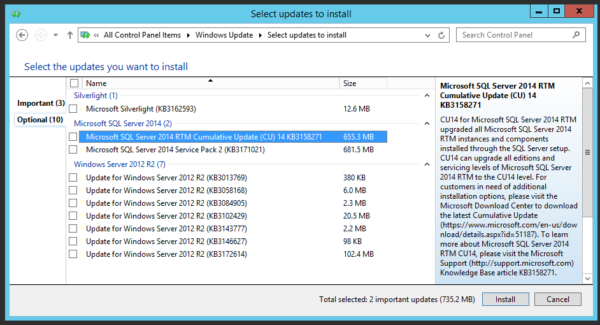
Weren’t SQL Server Cumulative Updates always included in Windows Updates?
Brent Ozar: Rob says, “I see this week in the blog that Microsoft is putting out SQL Server cumulative updates in their Windows updates. Weren’t those always in Windows updates in the past?” No. Service packs were. Service packs have been for the longest time, but cumulative updates popping up in Windows updates, that is new. Microsoft hasn’t gotten its act together either. I have a screenshot in that blogpost where it shows both CU14 and Service Pack 2 inside the same thing where it’s going to tell you to download a gig and a half of updates, and one of them just replaces the other.
Tara Kizer: In bigger organizations, you’re going to have Windows updates turned off on your servers and possibly use SCCM, System Center Configuration Manager, to manage your updates and what you’re going to be pushing to the servers. A lot of organizations on the SQL servers, you might push the patches to the server but you’re not installing them yet. The servers have already downloaded them but then a DBA comes along or a sysadmin and double-clicks on the bubble that appears and just installs it. Then you can reboot and you do your failovers.
How do I keep server objects in sync between different SQL Servers?
Brent Ozar: The man with the coolest first name in the world, Rowdy, asks, “I’m working on …” And yes, I know who you are, Rowdy. Because it’s not like, how many people do we know named Rowdy? There’s one guy named Rowdy and I recognize his last name. “I’m working on some scripts to ensure that our DR instances remain in sync with our failover cluster instance. So far, I’ve got scripts to check logins and SQL agent jobs. Next, I’m working to compare the contents of sys configurations. What else would you compare?” That’s such a great question.
Tara Kizer: I would stop and don’t reinvent the wheel. There’s tools out there that can do this for you already. I used to do all of this manually and you’re talking about a lot of things you’re going to have to check. Alerts, operators, besides jobs and logins, there’s a lot of things that are stored outside of your user database.
Brent Ozar: Is there any third party that…
Tara Kizer: I know Bill Graziano has a tool, I don’t know if that’s the most popular tool. He wrote one a few years ago, I know that he keeps it up to date. I’m not sure about other tools though.
Brent Ozar: What’s the name of it?
Tara Kizer: I don’t remember his tool.
Erik Darling: So that’s Bill Graziano, G-R-A-Z-I-A-N-O?
Tara Kizer: Yeah.
Brent Ozar: I’m going to go fire up Google.
Tara Kizer: I think he is scaleSQL.com.
Brent Ozar: Yeah. Let’s see here, I’m sure he’s got … yeah, go start there.
Tara Kizer: I think that there’s another tool that maybe people are using.
Brent Ozar: Redgate’s Schema Compare.
Erik Darling: SQL Compare.
Brent Ozar: Yeah, SQL Compare.
Tara Kizer: It does the server level? Okay.
Jason Hall: Toad has a server compare built in too, it’s not enabled at the moment, which is kind of a shame for this use case. You want to try to trial, you could at least do one and list off all the differences that it checks…
Tara Kizer: I’m not sure if they can hear him since he’s so far from the microwave… Microwave?
[Laughter]
It’s almost lunchtime.
Tara Kizer: Microphone. Jason was saying that Toad has it also, but it would require you to run it manually.
Brent Ozar: So what are he’s saying is go get the trial, it’s like 14, 30 days, something like that, for free. Then you could at least compare the two servers, see what it flags, and then that’s …
Tara Kizer: That’s true, yeah, and then you can script it.
Jason Hall: [inaudible 00:34:47]
Tara Kizer: Yeah, there’s a lot of things stored outside of your user database. Usually for me it was just logins and jobs and that was it. Not a whole lot.
Erik Darling: Good luck, Rowdy.
Brent Ozar: Good luck, Rowdy.
Why is instance stacking a bad idea?
Brent Ozar: Dan asks a question that I know is near and dear to all of our hearts. “My manager wants me to install a second named instance on an existing SQL Server because we have an app that requires its own named instance. What issues can I expect?”
Erik Darling: All of them.
Tara Kizer: I would want an answer to a question first from Dan. Is this a virtual machine or a physical server? If it’s a virtual machine, just spin up another virtual machine. If it’s a physical server, then… He says it is a VM. Why don’t you just spin up another virtual machine? Maybe tune down the other server if you don’t have the resources, and split them up. We don’t like the idea of stacked instances when there’s multiple instances on a server, and especially when it’s a VM, because you have options with virtual machines.
Brent Ozar: Somebody emailed us at help and asked, because they’d heard us rant against stacked instances several times on different webcasts. They said, “No seriously, what are the issues?” So we’ll just start brainstorming some of them. My big one is always security. If I have to get someone Windows admin rights because that vendor, if he wants his own named instance, he’s going to want to remote desktop in, and then he’s going to want to change things. I only want him breaking his own VM, not other people’s VMs. Patch timing, like when I’m going to have to patch this thing, Windows and SQL Server patches, when they’re going to do restarts, I’d rather have that separate. Because sooner or later this app is going to be like, “I can only go to SQL 2012 Service Pack 1,” and everybody else wants to go to newer, like 2014, then you end up peeling them off onto different VMs anyway. Different failover options, performance troubleshooting is a nightmare. Where is my CPU usage coming from? Then people will start playing around with affinity masking and they’re hardcoding how much CPU each instance can actually get, it’s just a big pain in the rear.
Tara Kizer: Yeah, CPU and memory would be my two biggest. I mean, even if you use Resource Governor, that can’t control everything.
Erik Darling: You’re using direct attached storage…
Brent Ozar: Oh yeah, yeah, yeah. [crosstalk 00:36:56] Fighting over the same SAN [inaudible 00:37:00].
Should I go to a training class or a conference?
Brent Ozar: Kyle says, “I was given the thumbs up to attend PASS this year but I will not be given any money on training or travel next year. I was looking into your performance tuning class or your senior DBA class online, but I’ve never been to an in-depth SQL course. I’m leaning towards one of the training classes instead of PASS. What would the difference be in the long run?” Oh, this is such a good question. I’ll give you my take. PASS gives you a lot of different 60 to 75 minute sessions. It is not really a start-to-finish drill down into one topic. However, PASS is better if you want to network, meet people, build a reputation in the SQL Server community, get help from other people in person, see vendors in the exhibitor area. It’s really more of a networking thing than it is an educational thing. Don’t get me wrong, there’s good sessions at conferences. My always experience has been, I’m only going to get to say five or six sessions per day, max. And three of them might suck, so I might get happy with two of them. Whereas, when you go to our training, let’s say four days straight, I guarantee no more than two sessions max will suck in any given day. Most of them will be okay. You don’t do that much networking. You network amongst the 15 to 30 people who are there in training and you meet them for life. But it’s just a different kind of setup deal.
How many people actually automate their restore checks?
Brent Ozar: Graham says, “I’ve automated …” Oh, Graham, I like you already.” I have automated my database restores and CHECKDB with the results of each process getting logged to a table. I know that this is recommended, but how many people actually do this? And is there a tool or something that can help automate this for me?” Do you guys have anything that helps automate restoring databases to another server?
Jason Hall: We do exactly this. I will tell you a lot of people do this, some of who have it sounds like done it the hard way. Apologize for the pitch here—but LiteSpeed for SQL Server, our backup and recovery tool, about a year ago introduced a feature called Automated Restore. The whole idea is you point Automated Restore to a folder. LiteSpeed’s going to scan through that folder and automatically find the latest backup set. So if you’ve got fulls, diffs, logs, all mixed into this folder, we’ll do the hard work for you and find the latest backup set to recover. We’ll recover it to a target system. There’s a lot of reasons why you may want to do this. One of which is just test the restore, right? The best way to know it can recover? Recover it. If the restore is successful, LiteSpeed can just drop the database, right? You’re done, let’s free up the space. Let’s move on to the next ones. You can now set up this round robin. The second reason you can set up an automated restore is exactly this: after your database is restored, run your CHECKDBs against it, so LiteSpeed can do that too. We give you all the CHECKDB options that you might want to set. After the CHECKDB is done, we’ll log the results into a central repository. Again, if it’s successful, you can drop the database, free up the space, and move on to the next one. If it fails, it’ll leave the database around, so you can get in there, figure out what’s going on, hopefully fix the issues. So yes, if you’re looking for a third party approach, LiteSpeed does exactly this. It’s probably one of our more interesting features we’ve added in a while to be honest with you. We’re starting to see a lot of traction. Certainly you can do it the hard way, it’s a lot of scripting though. There’s a lot of variables you have to consider: where your backups are, the types of backups there are, the parameters you need to use for recovery, and then all the CHECKDB options. So if you’re looking for a way to automate it, then yeah, LiteSpeed for SQL Server. If you Google it, you’ll get right to the product page. There’s a free 14-day trial for LiteSpeed. So if you wanted to kick the tires on it and make sure it does what you need it to do, you can run it for 14 days. Yeah, thanks for the plug.
Brent Ozar: I have to say too, people will often ask, “Why would I still get something like LiteSpeed when I get backup compression in the product?” This is one of the reasons why. I also like a better log shipping GUI. It’s easier to reinitialize whenever log shipping breaks. It’s easier for me to get undos for particular transactions. Danny, the developer, dropped a table, he even did a truncate table, which people will say isn’t logged—it is, but just not in the way that you would expect. LiteSpeed can go through and read your log files, reconstruct the table from scratch. It’s the easiest way to get back to a point in time before Danny screwed your database.
Erik Darling: It also does object level restores. So if you have a very large database and Danny the developer drops like 10,000 rows out of a [crosstalk 00:41:32] anything like that, you can restore a particular object and you’re much better off.
Brent Ozar: I knew you couldn’t resist.
Jason Hall: Since we’re shamelessly plugging, one of my favorite features of LiteSpeed, it’s actually a subset of our object recover functionality. We call it Execute Select. You can actually run queries against your backup files. I’m sure this has happened to someone before, where somebody comes in, maybe it’s an auditor, and they say, “Hey, I need to look at some records from four years ago.” Normally you scramble, you find a server to recover the backup to, you make sure you allocate enough space. You wait four hours for the restore to finish. You run your one query and then you drop the database. LiteSpeed just takes that query, runs it against the backup file, and you get your data back. You can output either just to Management Studio results set grid, you can output to CSV. If you want the data offline, it’s a really nice option. We started to see customers even start to kind of reevaluate their data management processes now. Think of this, you can use a backup file as a read-only data source. Think of the options this gives you for ETL. If you’re backing up your databases every night, why go back to the production system to extract data if you can just extract it from the backup file? Right, maybe you shave three hours off of maintenance Windows that you can now use for better index maintenance, scheduled recording, CHECKDBs, so absolutely. Again, thank you for the shameless plug but anyone out there who maybe has used LiteSpeed in the past, or has heard about LiteSpeed, please don’t consider it just a compression tool. It’s one of hundreds of amazing features the product has. Most of the enhancements we’ve made to LiteSpeed over the last several years have been more around these exact things. How do we recover from scenarios faster? How do we help you manage backups across large installations of SQL Server? Compression is great. There are millions of ways to compress data. If you come to me and say, “Hey, all I want to do is shrink my backups,” there’s lots of ways to do that. Many of them are included in SQL Server itself. But if you’re looking for a broader data management platform that will assist with both managing backup and recovery and helping you recover from scenarios faster, LiteSpeed is a great option.
Tara Kizer: Just to add two points to the question that Graham asked. I had this automated for mission critical databases that had performance issues when the CHECKDB would run on production. If we didn’t have any issues on the databases, then CHECKDB just ran there. It was just mission critical databases that have performance issues when CHECKDB was running. There are performance issues because CHECKDB is a very IO intensive resource, CPU. So on the lower priority, or if you have enough resources on your server, just run CHECKDB in production. My second point is, if you’re using a SAN, you can do SAN snapshots, that way you don’t have to do a restore. You can have your database, if you’re on another server, within a few seconds, and then run CHECKDB against that.
Brent Ozar: I’d almost say, like if your databases are less than maybe 50, 100 gigs, you should be running it in production, just because you want the fastest alerts that your data is no bueno.
How much does LiteSpeed cost?
Brent Ozar: Scott says, “Since you’re shilling LiteSpeed, what’s the rough pricing for the product?” You should probably contact your salesperson for that. I want to say it’s between $1,000 and $2,000 a server.
Jason Hall: You’re right on. General licensing right now is per instance of SQL Server. You can buy as many of them as you want, volume discounts apply.
Brent Ozar: Yeah, the more you buy, the more you save.
Erik Darling: Don’t accuse your salesperson of shilling, you will not get a good discount.
Brent Ozar: Unless his name is Curt Schilling.
[Laughter]
Where can I learn about replication?
All right, that gets us to the end of today’s questions. Mike asks, “Looking for training on replication, do you have any suggestions?” I would say books.
Tara Kizer: I don’t think that there is a… books, yeah.
Brent Ozar: Yeah, go hit Amazon. Hilary Cotter and Kendal Van Dyke have books on them, but other than that, I think that’s it these days.
Erik Darling: I think there’s a free Simple Talk book about replication. I couldn’t tell you who wrote it or what the name of it is, but I know Simple Talk and Redgate do a lot of the free e-books.
Tara Kizer: I learned in production replication. I’ve been using replication for many years and as you’re troubleshooting and trying to figure out why there’s errors, why there’s latency, learning on the fly and then Googling things. So I started in production with it.
Richie Rump: You’re book will be coming out when?
Tara Kizer: I will never ever again write even a chapter on SQL Server.
Erik Darling: I’d rather just learn a reliable technology.
Brent Ozar: So which training would you recommend for AlwaysOn Availability Groups? No, not ours either. It’s hard, that those kind of high availability and disaster recovery ones are, you really have to get really far in depth, and it’s whatever way your architecture is designed. Same thing with replication, so many different options for architecture. So welcome to real world doing it live.
Erik Darling: Allan Hirt has really good training for the HA and DR stuff if that’s what you really want.
Brent Ozar: Yeah, like three days, four days.
Erik Darling: He sets you up a lab, you get to play with the lab, you get to cover all sorts of scenarios that are just really hard to cover in a book.
Tara Kizer: Looks like Redgate has an e-book that Scott commented on. Fundamentals of SQL Server 2012 Replication. It’s a PDF.
Brent Ozar: There you go, nice. All right, cool.
Brent Ozar: Thanks, everybody for hanging out with us this week, and we will see you through the rest of the week on the Dell DBAs Webcast. If you want to go to brentozar.com/go/DellDBADays, will be the webcast for the rest of this week, and then we’ll see you at the next Office Hours as well. Bye, everybody.
Tara Kizer: Bye.
Richie Rump: Happy trails.
Brent Ozar: Happy trails.
Wanna attend the next Office Hours live? Register here, or subscribe to our podcast.
New Philly and San Diego dates for our in-person classes.
![]()