This week, Brent, Tara, Erik, and Richie discuss whether you should keep autoshrink on, AG multisite failovers, next version of SQL Server, SQL Server 2017 Vulnerability Assessment, SELECT INTO vs INSERT INTO, using Node.js with SQL Server, Using PowerShell for DBA tasks, the future of SQL Server for Linux, memory gateway query compile, VB.NET, patching, and more!
Here’s the video on YouTube:
You can register to attend next week’s Office Hours, or subscribe to our podcast to listen on the go.
If you prefer to listen to the audio:
Enjoy the Podcast?
Don’t miss an episode, subscribe via iTunes, Stitcher or RSS.
Leave us a review in iTunes
Office Hours Webcast – 2018-09-05
Is auto-shrink good when…
Brent Ozar: Rich is asking a question, but this also means Rich is not doing his homework from the training class, because Rich is in our mastering index tuning class right now. He’s doing such a good job on homework that I will let it pass. Rich says, “If you have servers that you can rarely get onto for maintenance, can you ever think of a time when you would keep auto-shrink on?”
Tara Kizer: Never; not even in a test environment.
Brent Ozar: And why not?
Tara Kizer: Why? I would wonder why you want to do this. There’s only bad things that happen. What issue are you trying to solve?
Brent Ozar: yeah, especially if you can’t get to them for maintenance, that makes me think that probably they’re growing on their own. Just let them grow out. Let them grow and go for it.
Why aren’t my multi-site AG failovers fast?
Brent Ozar: Sri asks, “Question on Availability Group multi-site failover – when we failover to the synchronous node, databases are failing over with any issues, but the web app that uses JDBC and the listener timeout isn’t reconnecting. What do we do to change the application’s max timeout?”
Tara Kizer: So it would be the connection timeout in the connection string. So there’s command timeout and then connect timeout, or connection timeout it might be. So those are two different things. You’d want connection timeout, but I suspect maybe your multi-subnet failover connection parameter, you either don’t have it turned on in the connection string, or it’s not working. I would wonder about your database driver and making sure that – you said JDBC JBoss. So JDBC 4.0 has multi-subnet failover. I would imagine you’re on that, but something’s not working there. You need to figure out – you know, check your connection string and see if multi-subnet failover equals true is in there, because that might be what you’re missing here.
Brent Ozar: And it’s worth to know too, just when your application sends a command, if they send a command or if their command is in-flight during the failover, it’s just going to time out. And it’s up to your application to go through and retry the same command. Like, JDBC is going to return a, hey, you know, your command timed out, and you have to go through and retry it. I say you, it’s your developers, not you.
Any word on the next version of SQL Server?
Brent Ozar: Mike says, “Any word on the next version of SQL Server?” The word is future… So we don’t know, of course, and anybody – I always say that anyone who knows isn’t allowed to say. Anyone who says, that means they don’t know. But I would say that Microsoft’s Ignite Conference is coming the third week of September, I think. It’s like the 20th through 24th. Last year at Ignite, they announced the next version of SQL Server and gave public previews. So since it seemed like they wanted to move to a yearly release cadence, that might make sense that they would announce the same thing at Ignite here in September.
Richie Rump: So is that going to be in Orlando, or?
Brent Ozar: You know, I don’t know. I don’t know where Ignite is at.
Richie Rump: Well let’s just hope they don’t put it in Chicago again because that didn’t go well last time.
Brent Ozar: I heard from several Microsoft people that they were like swearing on a bible they would never do Chicago again ever it was so bad.
Tara Kizer: What was the issue?
Brent Ozar: The food was unbelievably bad. It was legendarily bad because they didn’t have enough catering supplies to deal with like 30,000 people coming in at once, so they gave out cold sandwiches, cold fried chicken, then they would run out and it would be an hour before they would get more. There was a bus line going to and from the convention center because there was no hotels at the convention center; that can handle that many people, of course. And the busses get trapped at rush hour so people were on busses for an hour to get to and from their hotel and you would have walked fast. Terrible…
Richie Rump: Yeah, I think the bathroom situation was not optimal either and just people waiting in lines forever.
Brent Ozar: I love Chicago, but I would not want to go to a conference there. So that probably answers it there, I would watch at Ignite. The other thing I was going to say is, at the PASS Summit coming up in November, there’s a bunch of public sessions where people have said we’re previewing vNext here. Like, Microsoft has said we’re previewing vNext, so that means that it’s at least going to be publically demo-able in November.
Have you used the Vulnerability Assessment?
Brent Ozar: Heather says, “Do y’all have any experience with the SQL Server 2017 vulnerability assessment?”
Tara Kizer: I’ve never even heard of it. I don’t keep up to date on their extra tools.
Brent Ozar: I want to say it was an SSMS 17 feature and when they brought it out, they said things like xp_cmdshell is bad, you should turn this off. I’m like, really? Really? Anybody who’s SA can turn that on and turn that off anytime they want to and there’s, like, no tracing for it. So I’m not sure I take it really seriously.
Richie Rump: Does it scan your application for SQL injection? Does it do that for you?
Brent Ozar: No. Even the plans in the cache it doesn’t look at to see if they’re vulnerable. I’m like, it’s kind of cheesy. And they didn’t improve it at all…
What’s the fastest way to load a temp table?
Brent Ozar: Shaun asks, “If I’m inserting stuff into a temp table, should I do select into temp table or should I specifically say insert into temp table? Is there a performance difference?”
Tara Kizer: I mean, I think one of the issues with select into is that you might not get the right data types. There’s an issue there, so making sure that your temp table is created in the exact layout you want. So I usually do insert into if I’m in a stored procedure. If I’m just in Management Studio, I’m lazy and will do select into, just because it’s easier for me to write. I don’t have to do the [cray 0:05:21.0] stuff.
Brent Ozar: Yeah, Kendra wrote a blog post about this. There were changes in certain versions of SQL Server where you suddenly got parallelism where you didn’t before. And this matters a lot depending on how you define your code, and I never remember what the takeaway was. I always have to point people back to this. because I’m with Tara, I just go, I want to create my table explicitly, here’s the data types that I want, if I want a key, here’s how it looks like. I feel really bad saying here’s how I write queries these days because I am writing queries in Postgres and Richie’s right here and he sees my terrible queries and I know he’s just holding his mouth going, Brent, that’s not really what you do. You write toilet equivalent queries. They’re really bad.
Richie Rump: No, actually the one I reviewed yesterday, I was pleasantly surprised. I’m like, oh nice…
Brent Ozar: Which tells you that I usually write crappy queries, because he was pleasantly surprised by this one…
What are you wearing?
Brent Ozar: Darshan asks, “Tara, why the hat?”
Tara Kizer: I know, I was waiting for that. I’m surprised it didn’t come up before we started with the questions. I just didn’t have a chance to shower and that’s just what I had on when I took the kids to school. I don’t like my hair in a ponytail publicly and I needed it to be in a ponytail, so the hat’s covering that.
Richie Rump: So, Brent, why not a grey shirt?
Tara Kizer: Yeah, there you go.
Brent Ozar: Yeah, really, I need to get with the company uniform today.
Have you used Node.js with SQL Server?
Brent Ozar: Kevin asks, “Have y’all ever used Node.js with SQL Server?”
Tara Kizer: That’s certainly a Richie question.
Richie Rump: No, I haven’t. I have used it with Postgres with some pretty good success, but no I haven’t used it with SQL Server. That’d be a curious little test to do that. I don’t know if any – I’m assuming there’s a project out there to talk to SQL Server. I’ve never used it or any libraries around it. So yeah, maybe that’s something I’ll do in the future. It could be kind of fun.
How do I keep logins in sync?
Brent Ozar: John says, “I have two instances that should have the same logins and DB users and I’m planning on using the second server for reporting via log shipping of a couple of databases, but I think my logins are out of sync. How can I check and correct my logins if I need to sync them?”
Tara Kizer: You could just query sys.logins or whatever it is and look for the sid, but you may want to just drop them and move them over and make sure that you copy the sid. And Brent’s got the script out there that can do that for you. It will grab the password and the sid. But what you can do is you can transfer the databases over to that log shipped server and un-orphan them to avoid having to do it. But I like to get my sids in sync so I don’t have to take that extra step of un-orphaning them.
Brent Ozar: Do it once, get it right and be done with it. Yeah, so the – for those of you listening to the podcast, it is a link to Robert Davis’s script on transferring logins to a database mirror. The same technique works with log shipping, database mirroring, Always On Availability Groups, anything where you can create different logins on different servers.
I have an index with 2 partitions
Brent Ozar: Joe asks, “I have an index with…” What the… Joe, can you rephrase your question? I’m not exactly sure what you mean by that, with an index with two partitions. Usually, if people do partitioning, they do a lot more than two partitions. So I’m thinking there’s something lost in translation there.
Should I use PowerShell and nothing else?
Brent Ozar: Anna asks, “Do y’all recommend using PowerShell only for all DBA tasks?”
Tara Kizer: We’re the wrong company to ask…
Richie Rump: No, no, whoa. If someone said you have one tool to do DBA tasks with, PowerShell would never be my answer.
Brent Ozar: Whoa, that’s inflammatory. Richie, why would you say that?
Richie Rump: You know, command lines are good for certain things, but other things, I want more of a fully functioned thing and SSMS is that tool, right. I mean, it’s really the best database tool out there, so why would I go down to PowerShell for everything when the best tool out there is SSMS?
Brent Ozar: And we know people are going to disagree with us. We don’t manage lots of servers. So we tend to manage one or two servers at a time. Clients have us parachute in and do a really deep dive. I know people out there who have the opposing viewpoint. They’re like, if I could only use one tool for the rest of my life, it would be PowerShell. And that’s cool. I think you should learn one tool really well, whatever that one tool is, and you should be amazing at that one tool. None of us on this call would choose PowerShell to be that one tool, but I know there are folks out there who do, it’s just not us.
Richie Rump: I mean, that being said, you should use multiple tools. You should understand multiple tools. I mean, I rarely use SSMS anymore. I’m in other stuff as it is. So it’d only benefit your career to have multiple tools under your belt.
Tara Kizer: I’ve worked at companies where I’ve had a lot of servers. One of the companies I worked at, we had 700 SQL Servers and back then – because it’s been five years now since I worked for that company – PowerShell was a thing. We had our own thing to deploy changes to a lot of servers. So we were using management Studio’s CMS, the central management server option and we had some fancy scripts that would populate the CMS with all of our servers. It would call a database, a database, as we called it, and populate that. So we had the CMS already. I imagine these days that company probably is using some PowerShell because of the amount of servers and PowerShell is fairly flexible. It can do more than just SQL Server stuff, whereas, with CMS, you’re writing scripts T-SQL. You can be calling out to xp_cmdshell to do other things. So I probably would be using it for some things if I’m using a lot of servers. Anna follows up, she’s got lots of servers and five different versions. So it has its uses, but like Richie said, you don’t just only use that tool for all DBA tasks. You pick the right tool for each task.
Richie Rump: Yeah, I mean we get in these flame wars all the time as developers, c# is the best… no, it’s Python… and we write lots of words on lots of bulletin boards and hate other people, and the fact of the matter is c# really isn’t as good at some things, but it’s really good at others. And Node.js is good for this and maybe not good for that. And so we have to take the positives and negatives. And it’s better for me as a developer to understand those positives and negatives and maybe even know a few of those languages so I could actually go off and maybe do other projects that are interesting, but maybe not using the language that I prefer.
Brent Ozar: I’m going to ask you a follow-up question then; if you could only learn one language right now for starters, like the first language that you would focus someone to go learn on, what would be the one language you would pick?
Richie Rump: First is hard…
Brent Ozar: Assume that maybe they’ve already played around with programming before, but like one language to specialize in.
Richie Rump: Right now, languages are easier but they’re also harder at the same time. JavaScript you have all this async stuff inside of it. Python, maybe one of those ones because you could write a lot of stuff in very little code, but there’s also a pretty medium to large learning curve there. So I mean, I don’t know, c#, there’s a big learning curve there, good lord. Maybe, now that you have a gun to my head, I’d probably say Python, but there’s a lot of languages that are out there that are really worthwhile and they have really some good stuff. JavaScript is a good one because you could go anywhere with JavaScript now. You could do frontend, you could do backend, you could go cloud, not cloud, anywhere, JavaScript is running. But JavaScript is notoriously hard to learn and hard to master, so yeah, Python; why not?
So, about this SQL Server on Linux
Brent Ozar: Sri says, “What do y’all think of the future of SQL Server for Linux? Will it be widely used at the Enterprise level?”
Tara Kizer: I really don’t think it is. I think that the reason why Microsoft did this is because there’s a lot of anti-Microsoft people who don’t want to run Windows on their servers, so they’ve got Linux and maybe they need to use SQL Server because some third-party application that they’ve purchased requires SQL Server. But those third-party applications probably don’t even support SQL Server running on Linux anyway. I’ve got a recent client where they are very anti-Microsoft. Would an anti-Microsoft company run SQL Server on top of Linux? I don’t know. I worked for a company that was very anti-Microsoft. They were mostly Unix, Linux, and Oracle. We had a very large Oracle team, but we still had SQL Servers. We had, you know, five SQL Server DBAs supporting, like I said, 700 SQL Servers, and they were very anti-Microsoft. Would that company be running SQL Server on top of Linux? I bet you they’ve had discussions about it, but why? It’s such a limited set of features available. I don’t know. I don’t really see a future for it.
Richie Rump: I mean, is it going up against the free tools like Postgres? I mean, is that its competition, or is the reason it exists for some other reason?
Brent Ozar: Yeah it’s tough. Joseph says, “Regarding SQL Server on Linux, I just joined an Oracle on Linux shop that is being pushed into SQL Server by market forces.” I would love to see this. Market forces, is this like Jedis and they’re like, yeah this is the database platform you are looking for and they’re pushing it…
Richie Rump: Hadouken…
Brent Ozar: he says, “Microsoft SQL Server on Linux appeals to us just for porting purposes.” Like the skills that you already know in the operating system – I have passionate feelings about this; very passionate feelings about this. Is it hard for you to find Windows sysadmins? Probably not. I’m not saying that they’re cheap a dime a dozen. They’re still hard to find, good people. But is it going to be hard for you to find the documentation you want for SQL Server on Linux? Yes, that’s going to be much harder. There’s so much good documentation out there for SQL Server on Windows and it really falls apart for SQL Server on Linux.
Have you used Contained Databases in production?
Brent Ozar: Augusto asks, “Have y’all ever used contained databases in production?” That’s a no. that is a no, ladies and gentlemen. Yeah, no, I don’t think so.
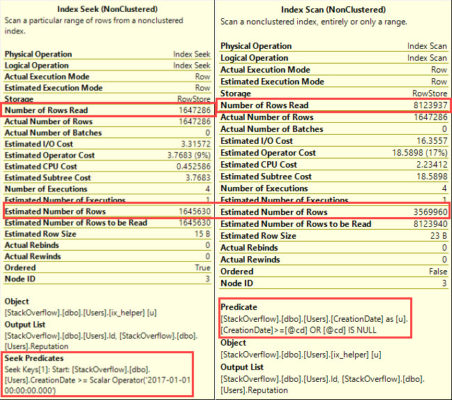
How can I fix RESOURCE_SEMAPHORE QUERY_COMPILE waits?
Brent Ozar: Alex says, “I’m fighting the poison wait resource semaphore query compile. I don’t have memory pressure. There’s only 80GB in use out of around a couple hundred GB and m CPU isn’t bad. Is there an issue with compile memory?” Yes, it means that SQL Server can’t get enough memory in order to compile a query. The fact that your server has a lot of memory overall doesn’t necessarily mean that a lot of memory is available to do query compilations. The term that you could Google for is memory gateway; SQL Server memory gateway query compile. And there’s a couple of blog posts out there from Microsoft talking about the gotchas with it.
Is VB.NET the Python of .NET languages?
Brent Ozar: Radu says, “VB.NET is kind of like the Python of .NET languages in terms of learning curve; it just got wrongfully accused lately.” I don’t even know where to begin with this, Richie…
Richie Rump: Okay, so I did VB.NET for a really, really long time. VB way before that, started in VB3. I understand your love for VB, but at some point, when even Microsoft stopped writing documentation for it and examples for it, you needed to get off of that and onto something else. Because when they’re not giving you the proper support and you can’t find – you know, new features come out and all of a sudden they’re not in VB and it’s in c#, there’s a lagging there. I wouldn’t start anything in VB.NET right now. There’s really no reason for it. The problem isn’t with VB.NET the language, the learning curve, it’s .NET itself. It’s the framework. There’s just so much going on there. Understanding the .NET framework is harder than learning the VB language. I could go on forever…
Brent Ozar: VB, I felt like when I was learning .NET languages, VB was the one that was most approachable to me because I knew VBScript. That was also the point where I stopped learning languages because I’m like, I don’t think real programmers – this is horrible to say this stereotype – I don’t think real programmers are using VB.NET. they’re going to kind of phase away from that, which means that my skills are going to get outdated fast. I need to learn something else, c#, Java, JavaScript, whatever. And if you’re a career developer, you probably have to have that love of learning new languages and frameworks. And assuming that you do, I would want to get away from VB.NET.
Richie Rump: Yeah, I love VB. Listen, don’t get me wrong, I haven’t coded it in at least a decade, but me going from VB.NET to c# was so seamless because I understood the framework and everything else is just syntax. But understanding the framework is the hard part of VB.NET, not the language itself.
Brent Ozar: God, it doesn’t seem to be getting easier either with the .NET Standard, .NET Core, all the different stuff that’s going on there…
Richie Rump: Of which I haven’t even touched because if you can’t figure it out yet, Microsoft, I’m not going to figure it out for you and go on your journey while you figure it out. So hopefully, this next version they’re coming out with, version three or whatever, maybe it’s even out by now because I’m not paying much attention, hopefully, that will be the one where they’re like, that’s the one, we’re sticking to it. But you wouldn’t believe, Brent, all the different versions and whatnot you need to go do hoops through for Core to make sure things work. It’s ridiculous.
Brent Ozar: I keep watching what Stack Overflow’s doing, with Nick Craver talking about their porting things over to .NET Core and he’ll be like, this is amazing, this is really good… This is terrible, oh, this is terrible, everything is broken… Okay, this is cool again. I’m like, if a guy as smart as you struggles this much figuring it out, I would be screwed.
Richie Rump: Nick is amazing. I mean, he’s going in and submitting patches for Core and stuff like that and I’m like, no I do not want to be fixing Microsoft’s code for them. That is not my job at all.
Which update should I apply?
Brent Ozar: Dave asks – he says, “The security update for SQL Server X Cumulative Update, which one should I apply and where?” Go to sqlserverupdates.com and at the homepage of sqlserverupdates.com we tell you what the most recent patches are and you can go from there.
Following up on VB.NET
Brent Ozar: Radu follows up with, “So the move away from VB.NET, that’s peer pressure. Otherwise, VB and c# still have language parity.” I’m going to leave that one alone…
Richie Rump: If you think so, that’s fine, but I mean, if I go to any sort of job site and I go VB.NET code versus c#, I’m going to see a lot better projects that I would want to get into as opposed to some legacy stuff with VB.NET. I mean, if you want to do VB.NET, that’s fine, go for it, man. Have at it. I’m not poo-pooing you. I’m not that developer. I’m not that guy, but for me, I want to be able to go on the projects that ring to me most because the work is what’s important for me, not the language.
Brent Ozar: There’s an interesting saying in business too; if you think about a grid of matrixes, you can either use old tools or new tools and you can either do old things or new things. The general advice is, you can do old stuff with old tools, you can do old stuff with new tools, you can do new stuff but using old tools, you never want to do new stuff with new tools. It’s just too much of a complex thing there. So if you love VB.NET, that’s okay, you can still do both old stuff and new stuff. You can go find new interesting projects, you can go work in cutting-edge industries, but just know that some of the really cool new stuff may not be open to you. The doors may not be open to you if you’re still using VB. If we were going to start a new project in the year 2018, I wouldn’t even think to hire someone with VB to do it.
Richie Rump: No, and it probably wouldn’t even be c#, frankly.
Brent Ozar: Yeah, yeah…
Richie Rump: And that being said, we may be doing some c# here soon, Brent, so…
Brent Ozar: For the execution plan analysis stuff? Yeah…
Richie Rump: In Core… Go figure, let me poo-poo it some more and we’ll end up doing it. That’s probably what’s going to end up happening.
We generate 900GB of log files every night…
Brent Ozar: Shaun says, “We have three databases on a SQL Server, each about 1TB in size. Every night, the data warehouse teams run nightly processing on those that generate about 300Gb worth of transaction log space for all three logs.” Okay, hold on a second here. Let’s think through that for just a second. You have a 1Tb database and you’re changing 30% of it every night. The name for this is Groundhog Day. What it means is that your ETL teams are wiping and redoing the same tables from scratch every day with no change detection. They’re just continuously overriding the whole reports table every single day and rebuilding those numbers. Long-term, just thinking way far out as a consultant, don’t do Groundhog Day type stuff; you’re going to have a bad time. It’s going to be tough around database mirroring, Always On Availability Groups, log shipping, your backups, just because of that rate of change, storage de-duplication, the list could go on and on.
His question continues, “I had them stop doing a shrink arguing that it’s just going to grow again every night, just leave it alone. Now I have all the storage guys calling me crazy, leaving those three files at roughly 300GB each. Am I crazy?” You’re both right. I mean, you shouldn’t be doing auto-shrink. You also shouldn’t be leaving 300GB log files around if they’re all empty all the time. But the answer isn’t to do shrinking; the answer is to go fix the Groundhog Day stuff.
Shaun follows up with, “Laughing out loud, yes that’s right, Groundhog Day is exactly what they’re doing.” Yeah, so you fix the Groundhog Day processes and then you’re fine.
Tara Kizer: It needs it every single day, so don’t shrink it. I mean, so yeah, let’s say you’re getting back 250GB, but you need it again tonight so you’re not really saving space at all.
We need help fixing Access blocking
Brent Ozar: John says, “We have a third-party app that has a Microsoft Access frontend…”
Tara Kizer: Ooh, boy. We were just saying, you know, VB.NET and c# are getting old…
Brent Ozar: I was going to use Access as an example too… “Connecting to a SQL Server table. Once the app is running and we try to update the table, there’s blocking. Is there any idea that would allow us to make updates throughout the day, like how do I have concurrency in Microsoft Access?”
Tara Kizer: Isn’t that the whole problem with Access, it’s like one user at a time. I mean, isn’t that like what it was designed for? Don’t use Access. Rewrite it…
Richie Rump: I think you can. There may be a setting or something where it’s locking the entire table. I mean, we’re talking now stuff that I did 25 years ago, I don’t recall. It was a very long time ago, but I would start messing with your connection settings, because it sounds like there’s some sort of weird locking going on there.
Brent Ozar: And I would always want to refer you to somebody who can tell too and it’s these guys, accessexperts.com. These guys specialize in just Microsoft Access. Really smart people, really friendly. They have a couple dozen employees I believe now at this time and they just specialize in Microsoft Access…
Tara Kizer: Wow…
Brent Ozar: Yeah, it’s absolutely huge. So I would check with them. Really friendly people, they can give you an idea of what it will be like to make it go faster.
How should I troubleshoot view definition mutex waits?
Brent Ozar: And then goodnight, the last question that we’re going to take, because we’re not going to have an answer – Alex asks, “What’s the best way to troubleshoot view definition mutex waits? Information regarding this wait is very scarce.”
Tara Kizer: Is it really a problem or is it just in your list of waits that are happening? What I would do is I would type in Google, and if there’s not much there, there’s probably a page from sqlskills.com, Paul probably has some information on it. Check to see if he thinks it’s an ignorable wait. But I mean, there’s plenty that I see in the list, but is it your top wait or your second top wait? Or are you just talking about number 70 in the list of waits that you’re looking up?
Brent Ozar: My first guess is, do some kind of logging to a table. Like, log sp_WhoIsActive to a table to see which queries are waiting on view definition mutex. My first thought is, have you got something like an application that’s continuously checking the contents of views, like a monitoring tool, to go through and assess slow queries? Maybe it’s written poorly and it’s trying to go get definitions of views. Or, you have insane concurrency, like really, really bad concurrency or something’s got – I’ve seen once where somebody had an alter view embedded in their code and they were doing that by accident. But if you look and see what queries are being blocked by it, I bet that’s going to be a big eye-opener.
Tara Kizer: He follows up and says it’s his second top wait. That’s crazy. I’ve never seen it even in the top 10 I don’t think.
Brent Ozar: No. Alright, well thanks, everybody for hanging out with us this week at Office Hours and we will see y’all next week; adios.
![]()