But Kendra, it can’t be that hard… after all, we have synchronous modes in Database Mirroring and Availability Groups, right?
Synchronous Commit doesn’t mean “zero data loss”
When we think about limiting data loss, the first thing we think of is a technology that lets us reduce points of failure. If every transaction must be written to two separate storage systems, we have a pretty good chance to have no data loss, right?
Maybe.
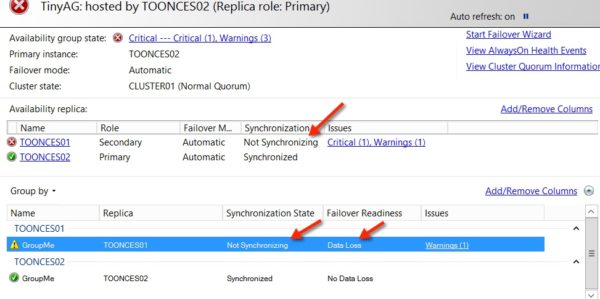
Let’s say you’re using a SQL Server Availability Group in SQL Server 2014 with a synchronous replica to do this. The secondary replica fails and is offline, but you don’t lose quorum. If you want 0 data loss, the primary needs to stop accepting writes immediately, right?
It doesn’t do that. The primary replica keeps going and writes can continue. Here’s what that looks like:
Tabloid headline: Synchronous AG Running Exposed! Scandal!
You could write custom scripts to detect the situation and stop the primary replica, but there’s a couple of problems with that. First, you’re offline, and you probably don’t want that. And second, it’s going to take some time to get that done, and that means that you don’t have zero data loss– you could lose anything written in the meanwhile. You could add another synchronous commit replica, but there’s obvious cost and support impacts, and you still aren’t guaranteed zero data loss.
Synchronous writes don’t necessarily guarantee zero data loss, you’ve got to dig into the details.
This stuff isn’t obvious
I’ll be straight up: I’ve been working with high availability and disaster recovery for a long time, and I hadn’t actually thought very critically about this until a recent chat room conversation with Brent discussing why it’s not super easy for cloud hosting providers to offer zero data loss in return for a lot of dollar signs.
Crazy facts: you can learn things from chat rooms and from the cloud. Who knew?
NEED TO PROTECT YOUR DATA? YOU NEED A FULL TIME EMPLOYEE WHO IS RESPONSIBLE FOR THAT.
If data loss is important to you, don’t just assume that you’ve got it under control because you’re paying a vendor to take care of it. If you look closely, you may find that nothing’s working like you think! When your data is important, you need to make someone responsible for ensuring that you’re meeting your RPO and RTO, and have them prove that it works on a scheduled basis. Their job title doesn’t have to be “Database Administrator,” but they need to work for you, and they need to take their responsibility seriously.
Want to Learn More About High Availability and Disaster Recovery?
We just launched our new DBA’s Guide to SQL Server High Availability and Disaster Recovery – a 6-hour online video course that teaches you about clustering, AlwaysOn AGs, quorum, database mirroring, log shipping, and more.
Psst - our new clustering/AlwaysOn/HA/DR course just launched, and it's seriously on sale.